What does Facebook Know? Predicting Your Personalities
3 things you will Learn from this post:
~ Your Facebook data has value, and bad guys are using it
~ We designed an algorithm that used Facebook data to predict your IQ and personalities
~ By using Matrix Completion technique in data preprocessing, we boosted our prediction by a lot!
Our* digital footprint* (the social media data) is huge. And our digital footprint is valuable, and extremely valuable to those big data companies.
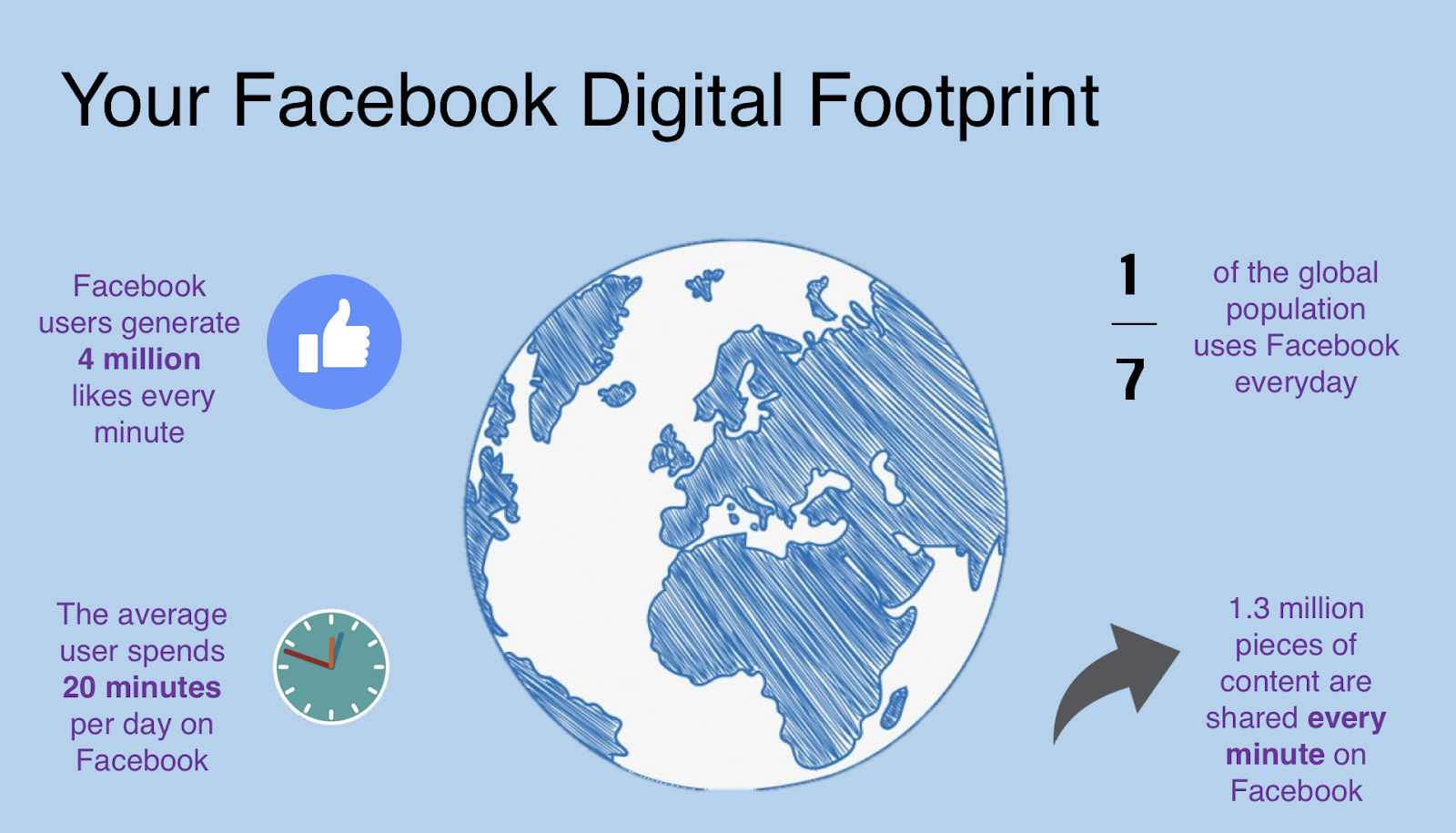
If you been on the news, you knew that you might be* one of the 87 million users* whose data was used by Cambridge Analytica for target advertising for the Trump campaign, and the data was accessed illegally.
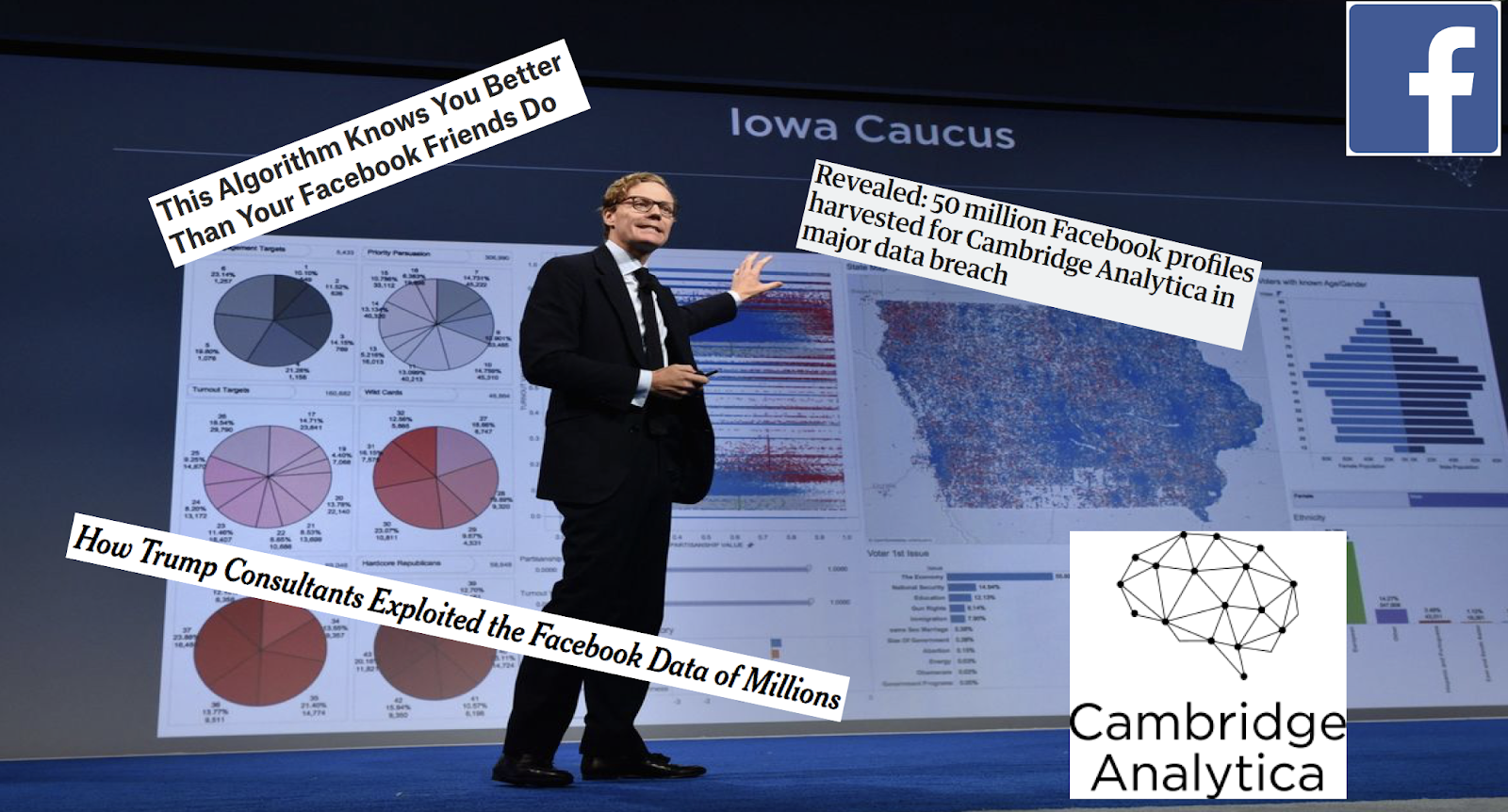
And there are larger implications about your data.
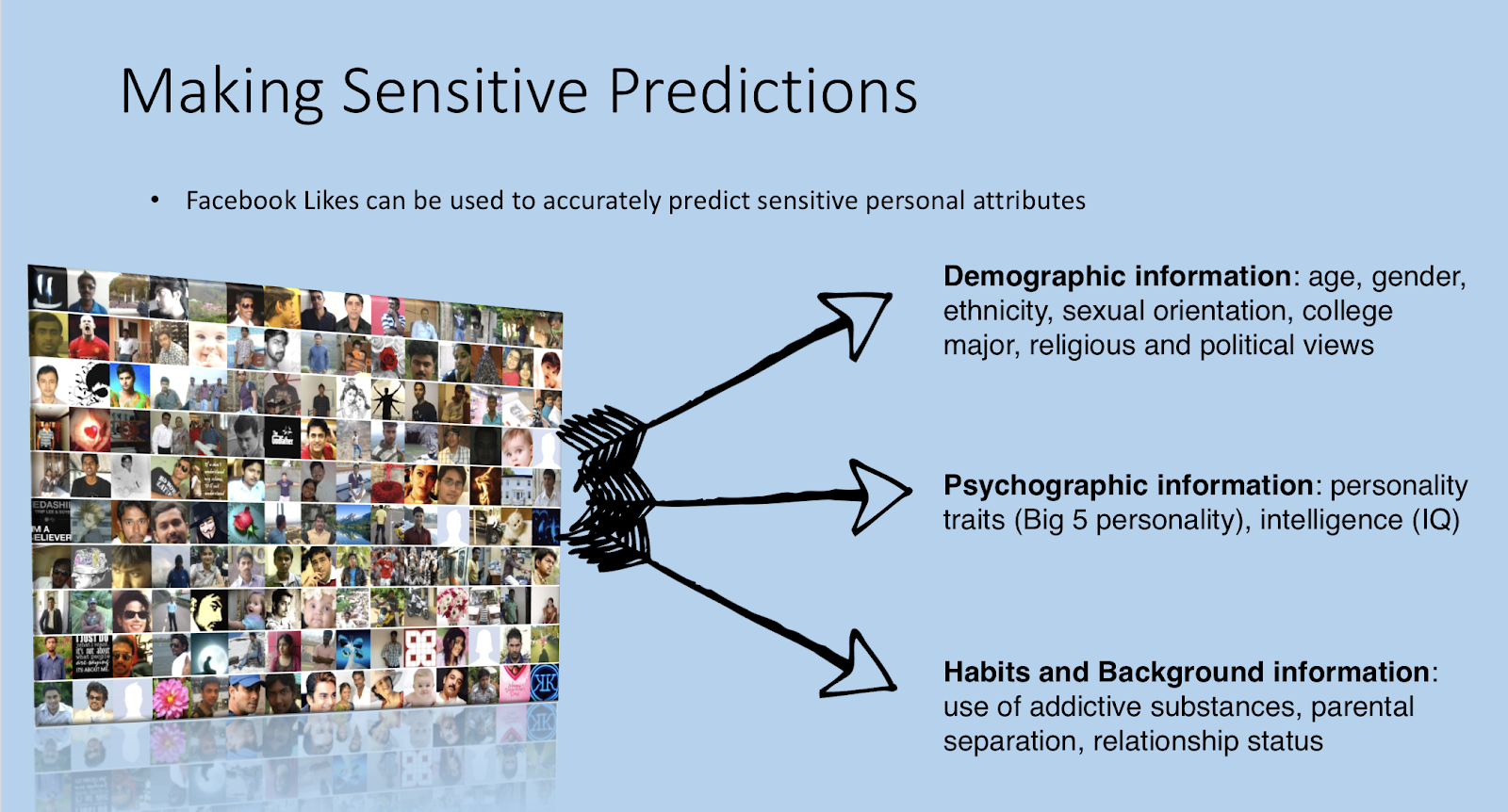
What can FB data predict about you?
A lot, it turns out…
It can predict your demographic information (i.e. your age), your psychographic information (i.e. your personality), and your habits and background information, even your relationship status. Isn’t that scary?
Before I talk about our research, I want to establish what type of previous research is out there for predicting attributes about rationality. *Kosinski et al *has introduced us this great scheme to use. It uses user-like sparse matrix of Facebook to predict people user’s personality, age, and gender.

Their steps are as follows:
~ Trim the user-like sparse matrix to limit only Users with 50 + likes and (Facebook post) Likes with 150 + likes
~ Reduce the dimension of the data from high dimension (one hot encoding of Likes) to 50 linear components using SVD
~ Use linear regression to train, test, cross-validate, and predict personalities

Using linear regression, they were able to predict the Big 5 Personality Test scores (OCEAN score). Each user here took the big 5 personality test online, and received a score.
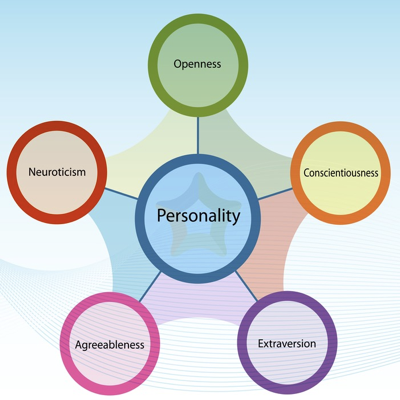
Here’s the Big5 test if you want to take it
Comparing its prediction to its true score (which is based on their online test and is arbitrary), Kosinski et al gets a decent correlation (r). It shows how well the prediction values correlate with the true data.
Here’s how they perform. And we are going to reintroduce them when we are showing our values
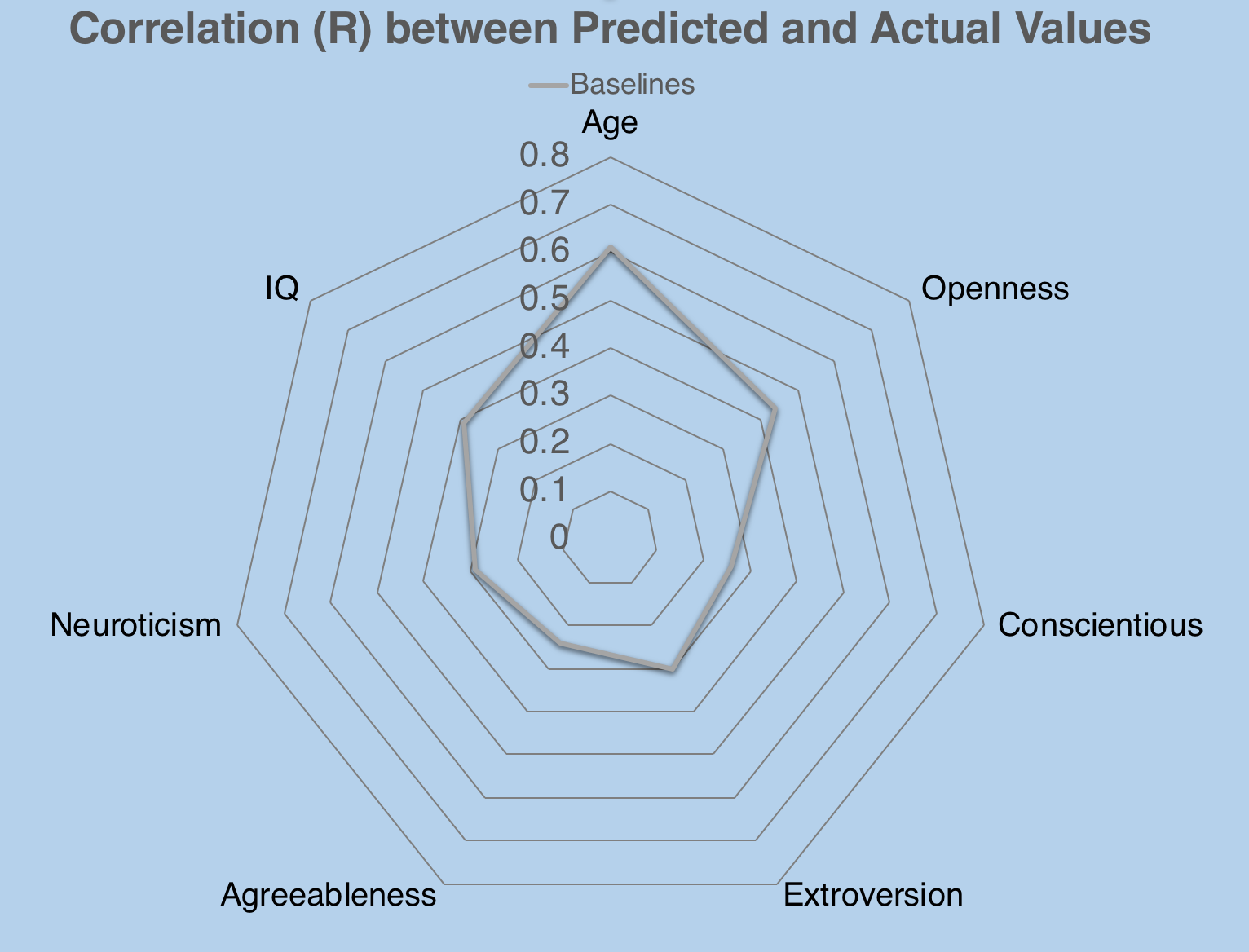
What we are curious is that how can we improve its prediction? Should we use better model? Or can we pre-process the data better?

Take a step back, and I want to introduce you to my friend Joe. Joe is a fictional character that we created. Although he’s my friend, I don’t know him very well. In fact, the only information I have about him are the 26 Facebook posts that he clicked “Like”.
I know that he likes posts such as “Coca-Cola”, “Fly the American Flag”, and “Disney”. So he get a “1” on those cells.

But we have no idea on Joe’s opinion on the Beatles or Katie Perry. So he got a “0” on all other 36,000 cells.
Previously, those cell has been treated as the value 0, meaning that Joe has seen every single of the 36,000 Likes but liked only 26 of them, that’s not a good way of coding it.

Since we do not know whether Joe has seen the posts but not Liked it, or he has not seen it at all, it’s better to err on the side that he hasn’t seen them at all. It’s not likely that he has seen even 7,000 (5%) of those 36,000 specific posts.
Wouldn’t it be nice to know what’s the chance that he like the other 36,000 posts?
And that’s exactly what we did. With our algorithm, we predict that Joe has 39% probability to like Katie Perry, 37% probability to like the Beatle, and only 1% chance to like the Hayao Miyazaki, the anime god. But how did we do that?
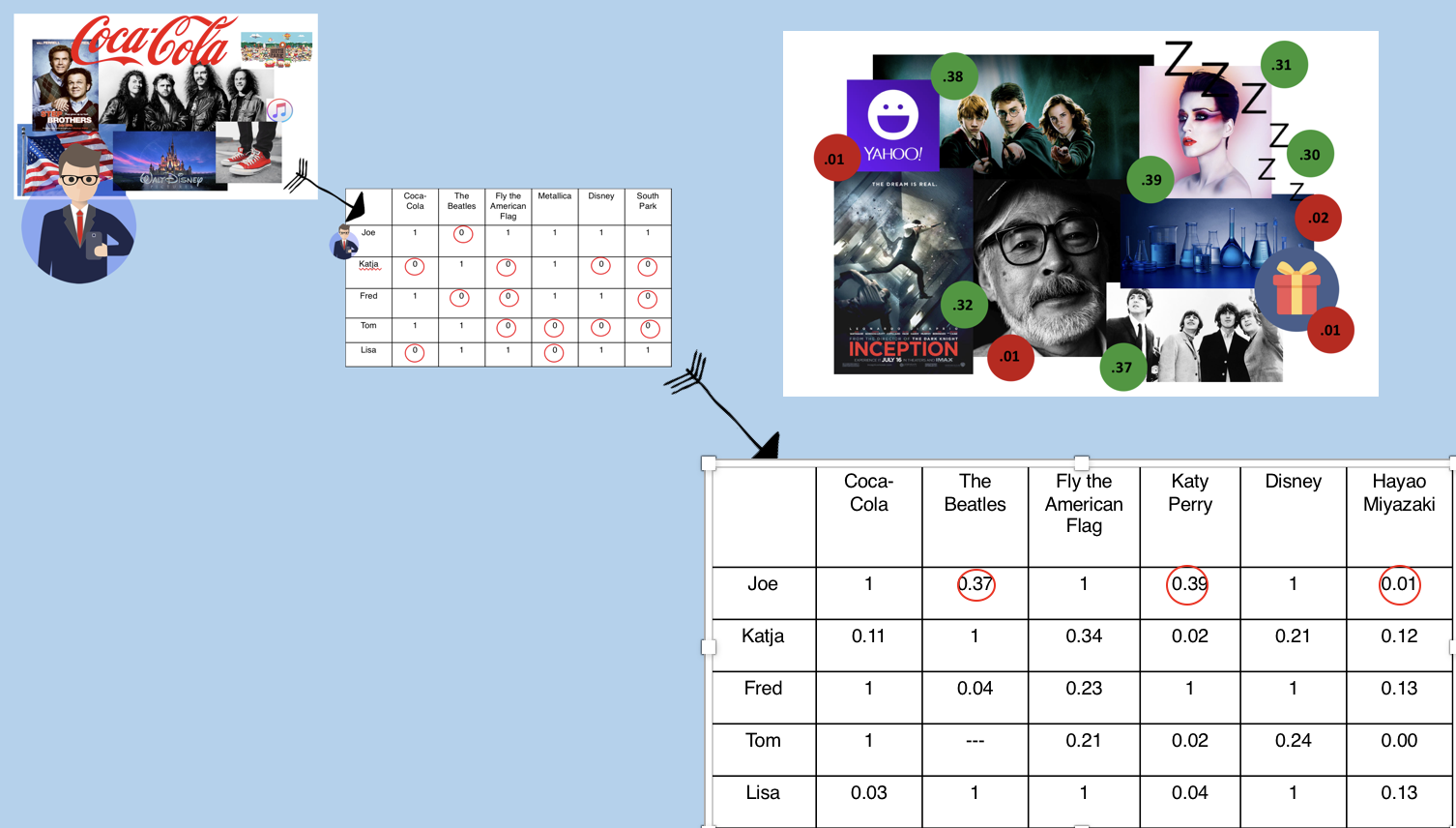
Here we encounter the problem of missing data and sparse matrix. Sparse matrix is a matrix that has a lot of “0”s. In this user-like matrix, 99.6% of the cells are “0”. But if we treat those “0”s as missing data, how can we guess a value for each and impute them?
It is at this point that we realize our problem is not unlike theNetflix Challenge, a classic matrix completion problem. Basically Netflix wanted to improve its movie recommendation algorithm. So it throw out this massive sparse matrix of user-movie data, and offered $1 million to the team that could best predict how users would rate each of their unseen movies.

The winning team used a statistical method called Alternate Least Squares (ALS).
Here’s the algorithm (a YouTube tutorial) :
~ factoring (SVD) Matrix R into matrix U for Users and matrix L for Likes
~ iteratively fill in the U and L until error is minimized
~ Multiply U and L together to get back R_imputed.
~ All the missing cells are now imputed with a number between 0 - 1 (for probability of like)

A famous Stanford professor by the name of Trevor Hastie wrote a package called softImpute, which revolutionized the computation and accuracy to realize the ALS matrix completion.
The code is actually really easy. For the full implementation, see this other blog post I write.
library(softImpute) M1 = as(M,“Incomplete”) # change dgCMatrix type to incomplete fit = softImpute(M1, rank.max = 10,type = ‘als’, lambda = 15, trace.it = TRUE, maxit = 10) Mimp=complete(M1,fit)
So, how does our model perform?
Just by this pre-possessing step along, we are able to have an at least 10% improvement on features Age, IQ, Openness, and Neuroticism.
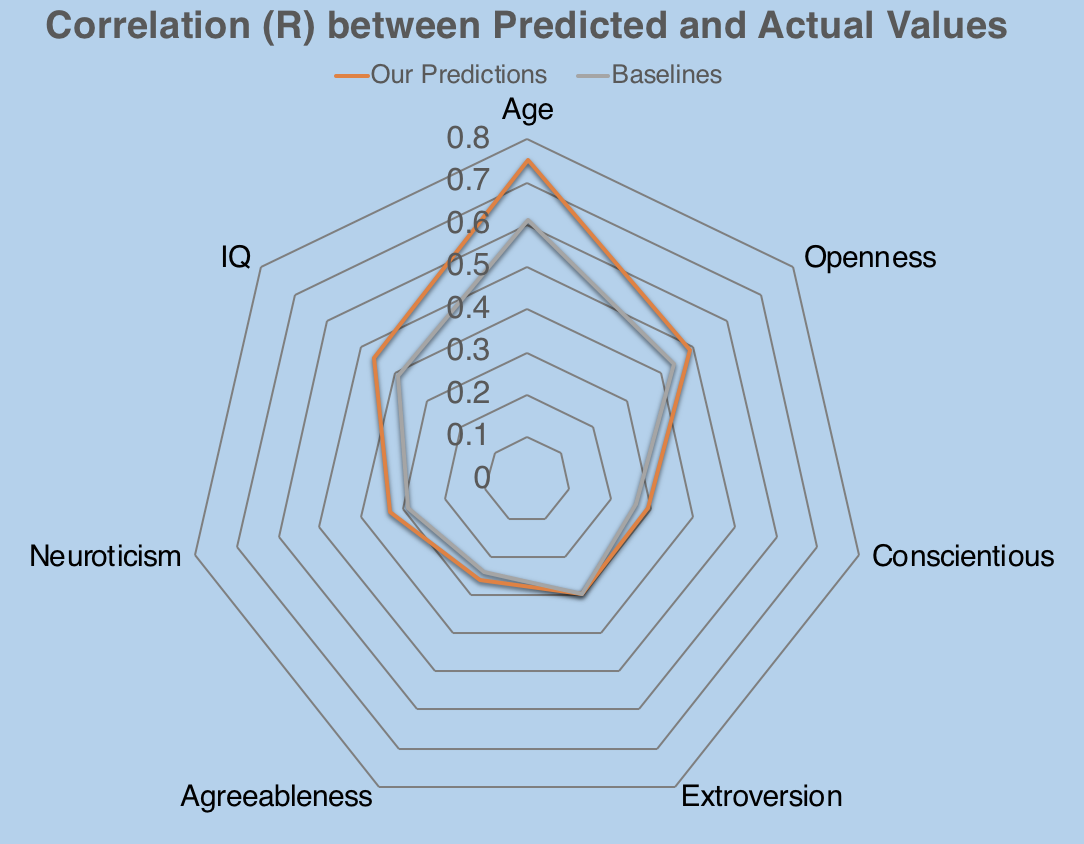
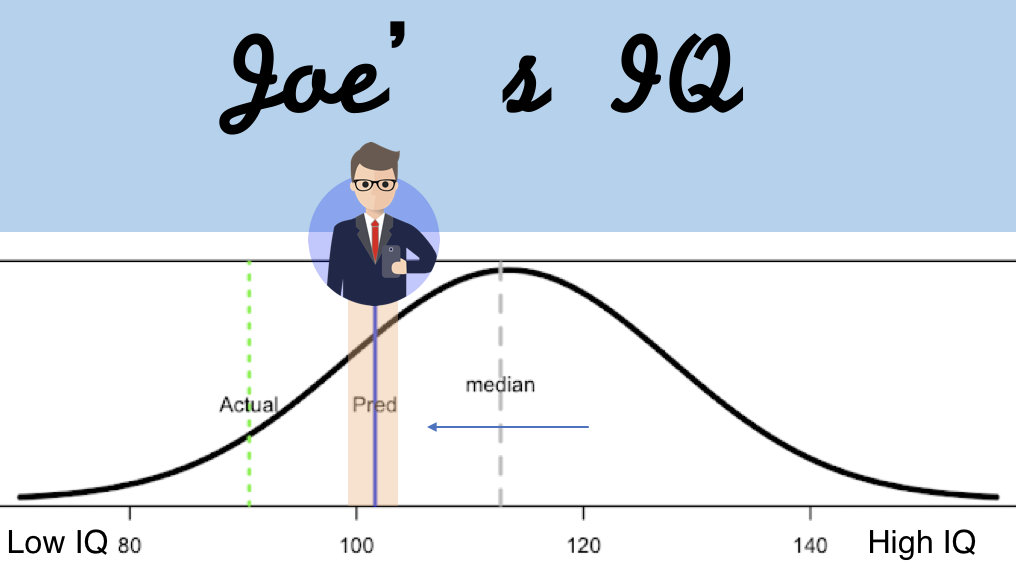
So, what do you think Joe’s IQ is? Does he have a low IQ, or a high IQ? Based on those likes.

Well, we predicted that Joe has a low IQ (the blue line), one standard deviation (std) below of the median IQ (the grey line) of our sample. And actually, Joe has one of the lowest IQ in our data (the green line) . His IQ is only 87, two standard deviations from the median.
We can do the same for all his personality traits. If you look at the arrow of the prediction, all are pointing at the same direction as the true value.
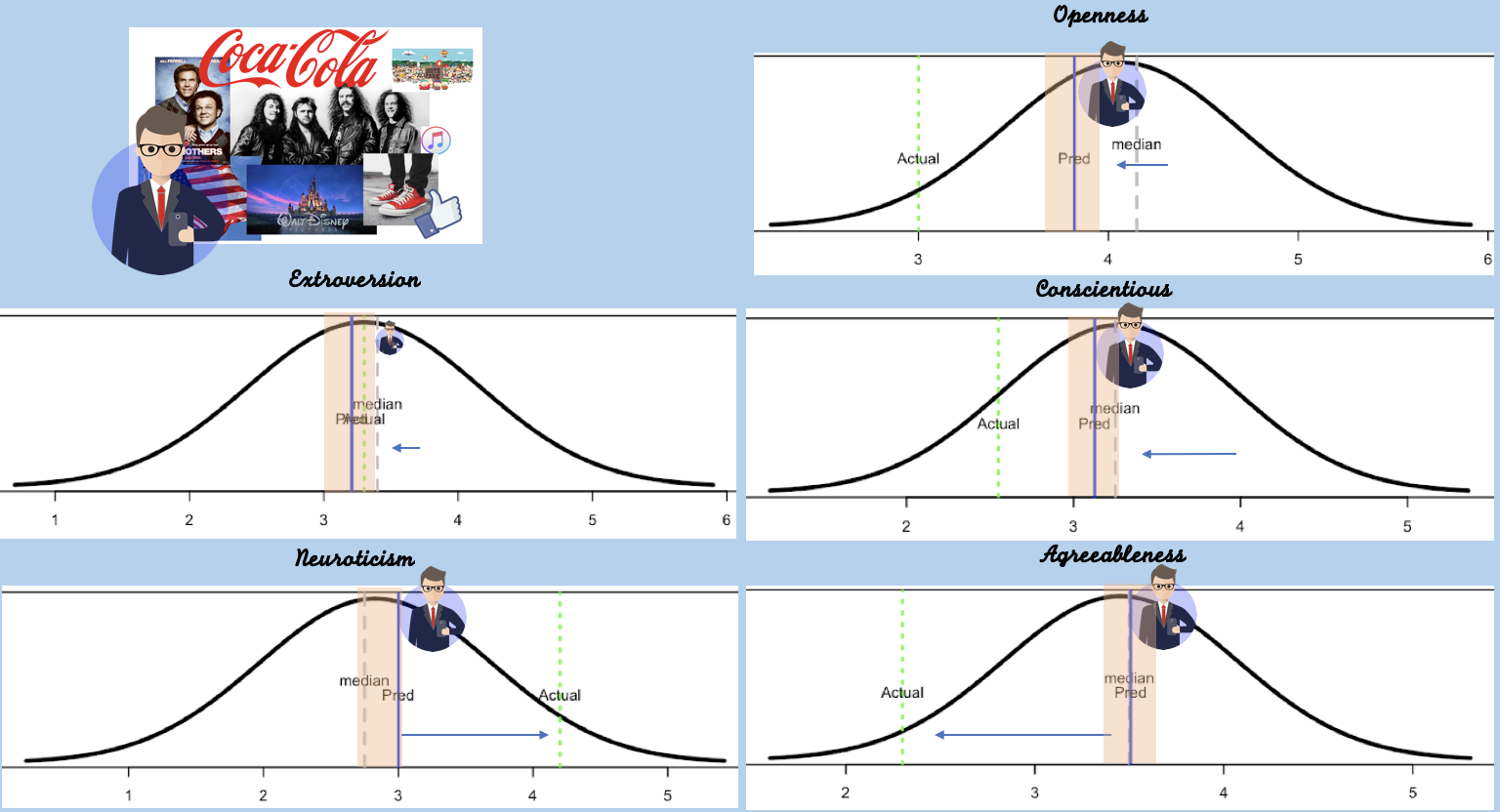
It shows that if all use all our predictions as the binary classifier of the features, we would have predicted “correctly” that Joe is low in Openness, Extraversion, and Conscientiousness. He is high on Neuroticism. We did not correctly predict that he is low on agreeableness.
The accuracy of this classification is not a coincidence. It does not hold only for Joe. for attributes for all users, 63% of the classifications were predicted correctly.
After becoming omniscient gods, what can we do with it?

Today, May 3, 2018, as I’m writing this blog, Cambridge Analytica shut down, 2 months after the data leak scandal. We do not tolerate companies like Cambridge Analytica to exploit social media data for voter manipulation. But by correctly predicting your personality and intelligence informations, Organization can also make the world a better place.
 Dating apps like Tinder can enhance matching-making by connecting people with compatible personalities
Dating apps like Tinder can enhance matching-making by connecting people with compatible personalities
 Ecommerce giants like Amazon can email you coupon of the goods you actually want to buy.
Ecommerce giants like Amazon can email you coupon of the goods you actually want to buy.
 Non-profits like the Gates Foundation can connect people with charities whose cause they truly care about.
Non-profits like the Gates Foundation can connect people with charities whose cause they truly care about.
So, after seeing what the good guys and the bad guys can do using your Facebook data, would you be willing to share it, or hide it?