What is the True Cost of Spam?
In March 2019, a landscaper named Matthew received a lead from Company T, a marketplace where to hire for local services. The customer seemed to be high intent. Only after long messaging did Matthew realize that this customer was a spammer trying to scam money from him using a Nigerian Prince scheme—a typical way to ask for money upfront with the promise of big return in the future, which of course, would never happen. Frustrated by Company T’s inability to prevent spammers, Matthew, who spent $1600 a month on Company T prior to the incident, left the platform.
At Company T, we utilize a machine learning model to catch customer-disguised spammers from contacting our pros. Despite our best efforts, about 4% of pros have been spammed at least once in the year 2019. Quantifying the incremental spam impact against pros in terms of revenue loss is crucial: such a metric could not only help to adjust the model decision threshold, but also inform the goals and the resource allocation on spam detection for the Trust and Safety team.
The metric: Cost Per Pro Spammed
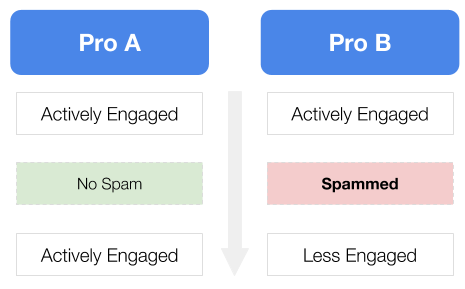
Conceptually, Pro A and Pro B would have a different journey like this: while Pro A stays actively engaged with the Company T platform, Pro B would become less engaged once Pro B gets spammed. To Company T, this would mean a pro in the end would spend less money to find new customers on the platform in the future. This revenue loss metric is termed: Cost Per Pro Spammed.
Quantifying the Cost Per Pro Spammed metric is crucial for the spam model due to the following trade off: if we want zero pros to be exposed to spammers, we would ghost all the slightly suspicious customers. The number of customers incorrectly ghosted would be high. If we want no real customer to be incorrectly ghosted, we could simply ghost no customer.The number of pros exposed would be high. (see equation)

Before this study, in V0 of the spam model the threshold was set arbitrarily. Plugging in cost per pro spammed metric, the only unknown variable, into the equation, we could optimize the model threshold and minimize the revenue cost of spam.
Why do we need causal inference?
To get the Cost Per Pro Spammed number, we want to calculate the incremental revenue loss for that pro. In other words, had the pro not been spammed, how much more revenue would they generate for Company T? Commonly, this type of problem is best solved by setting up an AB test experiment. We would randomly assign a treatment and control group and compare the difference in revenue in the end. However, with the treatment being getting spam contact, it is not ethical to harm our pros.
Causal inference, on the other hand, is a research method favored by economists. Looking through historical data, researchers would find synthetic control groups and natural experiment ground (where they have good reason to believe that the treatment and control group were created nearly randomly), so that they can estimate the incremental treatment effect without running an experiment.
Why would a pre-post analysis not work?
The first thing I did was a pre-post analysis on the 30d revenue difference for all pros who got their first spam in 2019. While I expected to see the revenue pro spent on Company T decrease in the 30 days after getting spammed, the average spent actually increased, from $66 to $71. Why would a pro spend more after being spammed? It turns out that the time when a pro was spammed is correlated with other confounding factors that increase a pro’s spend. Some likely explanations include that spammer activities increased during our big promotion campaign periods in Q1 2019, or that the pro’s first spam exposure happened generally as he was ramping up on the platform. The counter intuitive result showed us that merely comparing spammed pros to their pre-spammed self was not good enough because we failed to control for seasonality and pro tenure. **
Natural experiment part 1: How did a disaster in ML provide a gift to causal inference?
To estimate a reliable treatment effect, we need to find unspammed pros similar to the spammed pros for a difference in difference test. A difference in difference (DID) test can be viewed as a double pre-post test, comparing the difference between the difference in pre-post test for the treatment group and control group. This method would kill off any confounding longitudinal effects unrelated to treatment, as long as both treatment and control experience the same confounding effect.
Since we cannot do an AB test, we need to have a good control group for a DID test. We cannot use our entire unspammed pro population as the control. Why not? Because the average spammed pros are inherently different from the average unspammed pros; they are most likely our most engaged pros. A spammer, more likely than not, would go down the list of our listing page, and contact the pros in their ranked order. In other words, if you did not get spammed, you probably did not rank high enough.
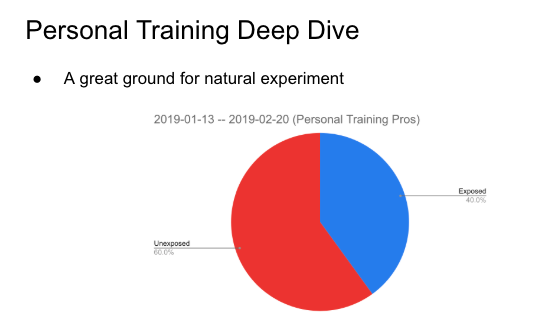
Luckily, we have a better control group. In Jan 2019, around 40% of the pros in our Personal Training category had been exposed to spammers. It was an unforeseen challenge for our marketplace trust and safety team and spam model, but a great natural experiment for causal inference. Since almost half of our pros were spammed, we have more reason to believe that the spammers were less discriminating in their targeted pro selection.
Controlling for revenue pre spam (beta2) and average search rank (beta3), we were able to get a statistically significant result for beta1, the spam impact. A spammed pro in the Personal Training category on average spends $4.75 less (25% of the median) than an unspammed pro in the next 30 days.
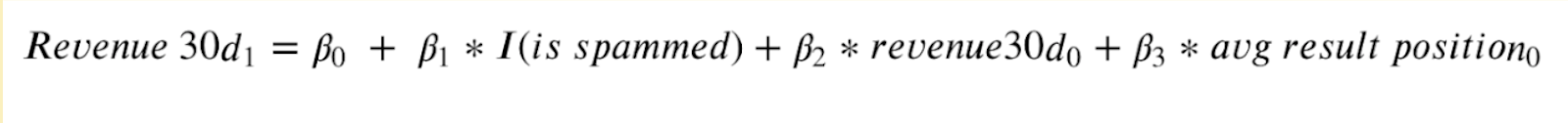
Despite this promising finding, the personal training spam impact is not generalizable to all 500 categories on Company T. For one thing, the average 30d revenue spent pre spam is $66 across categories, while only $20 for personal training in Jan 2019, a low season for Company T.
While encouraged by the initial results, I felt like we had gone the full circle only to start over again. We needed to go back to the drawing board to find a better control group, one could account for all categories at all times. The question is, where is such a group?
Natural experiment part 2: spam eligible pro model
Let’s revisit a pro’s journey. Pro A and B started on Company T actively engaged. Pro B got spammed, and became less actively engaged. We already talked about, due to selection bias, the average unspammed pro on the left could not serve as a good control group to compare against the spammed pro. However, there was a subset of the unspammed pro that we believed were much better control groups. There was a Pro C, who was spammed but not exposed. Why not? Because our spam model caught the spammers before they could reach Pro C. From the spammer’s perspective, these spam eligible pros were likely to be just as highly ranked and active as the spammed pro. But from Pro C’s perspective, he was unaware and unaffected by the spam.
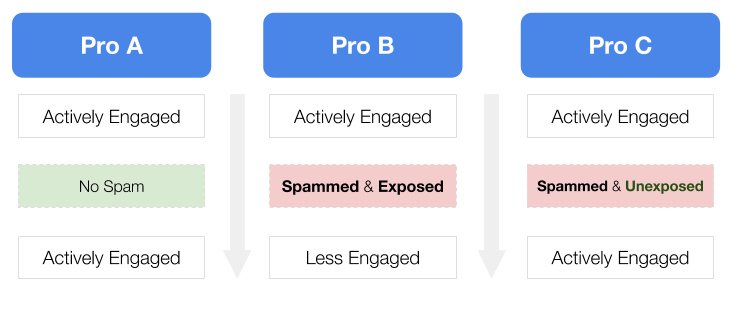
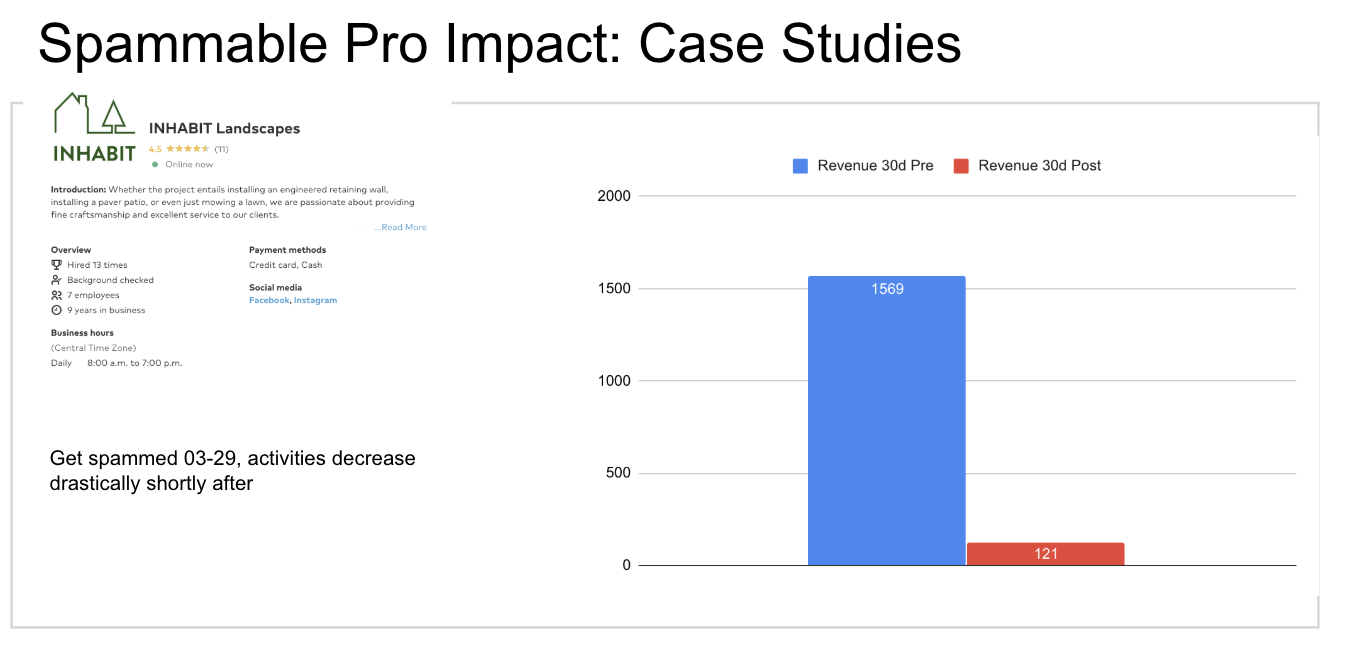
In this Spammable Pro Impact Model, we found that the spammed pros in average spend $10.7 less (stats sig, 16% of the median) than an unspammed pro in the next 30 days, with a few more controls on the pros tenure, experience, and response rate.


With the Cost per pro spammed quantified, we plugged in the numbers on Cost spam, and optimized the threshold for the spam ghosting model.
What can we do with It?
The calculated and fine tuned threshold now allows us to make these crucial decisions to treat spammy customers.

More importantly, the Trust and Safety team is now using this metric to set quarterly OKRs on spam prevention. The quantified spam impact cost is guiding the team to allocate sufficient resources to proactively combat spammers on Company T.