When Pornhub Meets Data Science
This project was presented during my final stats class at Duke. It was a hilarious joke project. While I relied on data to tell its story, don’t quote this as my personal sex view. :)
I highly encourage you to checkout my voiceover of the web app for this project.
Sexual desires and preferences have been a hard topic to study due to their sensitivity and privacy. In this project, I scraped 21,557 videos from the top 573 pornstars on Pornhub.com, to gain insights about what contributes to success, to both a video and a pornstar, defined by the video views and video ratings. The models find big cup size, young age pornstar, short video length, short video title, and a monogamous scene are the most significant predictors to increase the favorability of the videos and pornstars. To better visualize the specialty of each star, a shiny app with TFIDF word cloud of video titles for each star is created.
Does size matter?
Does size matter? What’s the optimal age for a star? Do people have better experience in watching many short videos, or skimming through just a few long videos, during a sitting? These are the questions both Pornhub and social scientists are trying to answer. However, if the study of public opinion in politics is difficult due to the survey constraints such as voluntary response bias and social desirability bias, the study of sexual preference, being a sensitive and private topic, is even more challenging. Yet, while people might falsify their preferences during surveys, they are by and large honest during private internet activities. In this project, I aim to identify the drivers of sexual desirability, at least in masturbation.
How to webscrape 20k porns?
The data is collected through scraping the pornstar bio pages on pornhub.com, which contain not only the biological data of the pornstars but also at most 50 of their videos. There were over 15,000 pornstars listed, and my plan was to scrape all of their data. However, I realized that there were significant missing data problems even in the top ranked 50 stars. Believing that additional stars would not contribute to noise more than signal if I go too far down to the list, I ended at obtaining data for the top 573 stars, and their 21,557 videos.
During the web scraping, the website kicks me out when it identifies the scraper. In response, I put a time-out between each loop — a random number sampled from a truncated normal distribution with a mean of 10 sec – to mimic natural browsing behavior.
The collected video dataset has these predictor variables: number of actors, video length, video title, and the number of characters in the title, which video rating as the response variable.
The pornstar dataset has mostly biological predictors: gender, dimensions (bust, waist, hip, and cup size), height, weight, active status (binary), and age, with total video view as the response. Although I have two other potential response candidates: ranking and number of subscribers, the video view variable is the one with the least missing data. In addition, the dimension variables are 73% missing on the site. To deal with this problem I used multiple imputation, because the dimension variables are indeed significant. The active status and gender variable were dropped, because over 99% of the stars are women and active artists.
Fit a model on a (sex) model
I used GBM (gradient boosted regression tree model) because of its ability to fit nonlinear data. When I first fitted a logistic regression to predict video quality (Good: Rating > 80%), none of the coefficients beside cup-size were significant. This model misspecification failure is due to the fact that some of the predictors are not linearly associated with video quality. For example, we simply could not say that a 1-year increase in age associates with a 1% increase in odds of the video being good. It’s much more an inversely U shaped relationship intuitively.
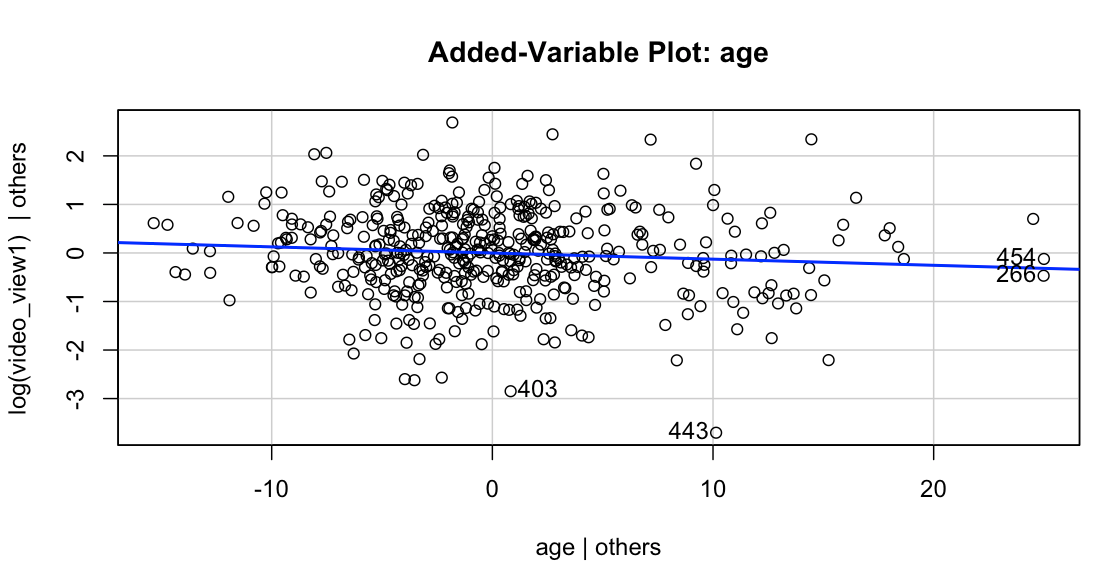 Added Variable Plot of age provides zero insight
Added Variable Plot of age provides zero insight
Tree models, on the other hand, do not require the assumption of linearity. In addition, tree models also bypass the problem of multicollinearity between predictors, such as weight and height, and dimensional variables with weight and height.
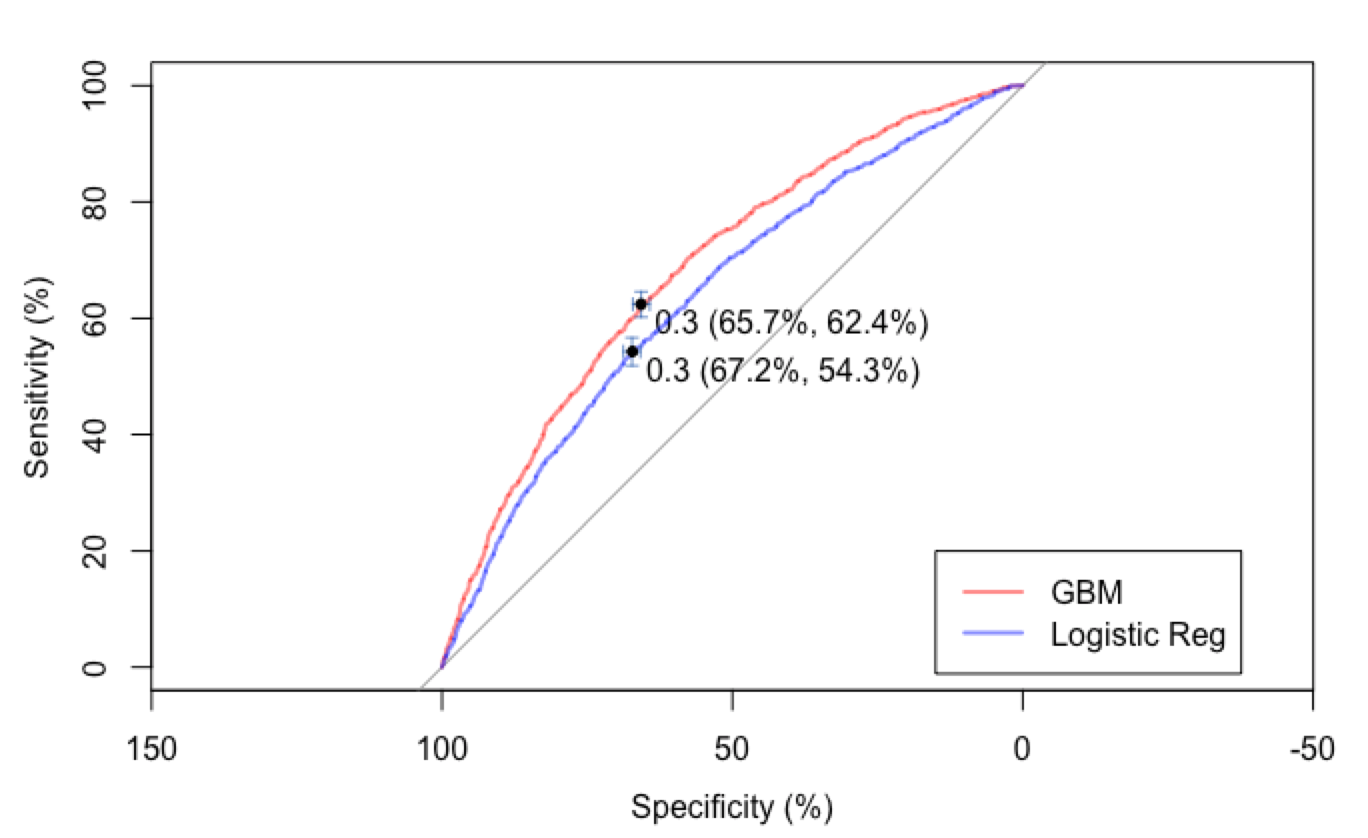
I prefer GBM over random forest for its additivity. Because GBM iteratively fit weak trees on the residuals, it prevents overfitting while achieving a high predictive power. As we can see from the ROC curves, GBM outperforms logistic regression in prediction, while providing insights through partial dependence plot and relative variable influence.
**Model Result—Part 1: Video rating **
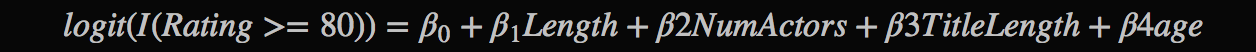 Logistic regression model, was replaced by GBM while all the predictors remain the same
Logistic regression model, was replaced by GBM while all the predictors remain the same
For classifying video rating ( >= 80%), the GBM model outperformed logistic regression model in both AUC (area under the ROC curve) and true prediction rate (.71> .67). Given limited scrapable features from the website, the 71% true prediction rate is satisfactory.
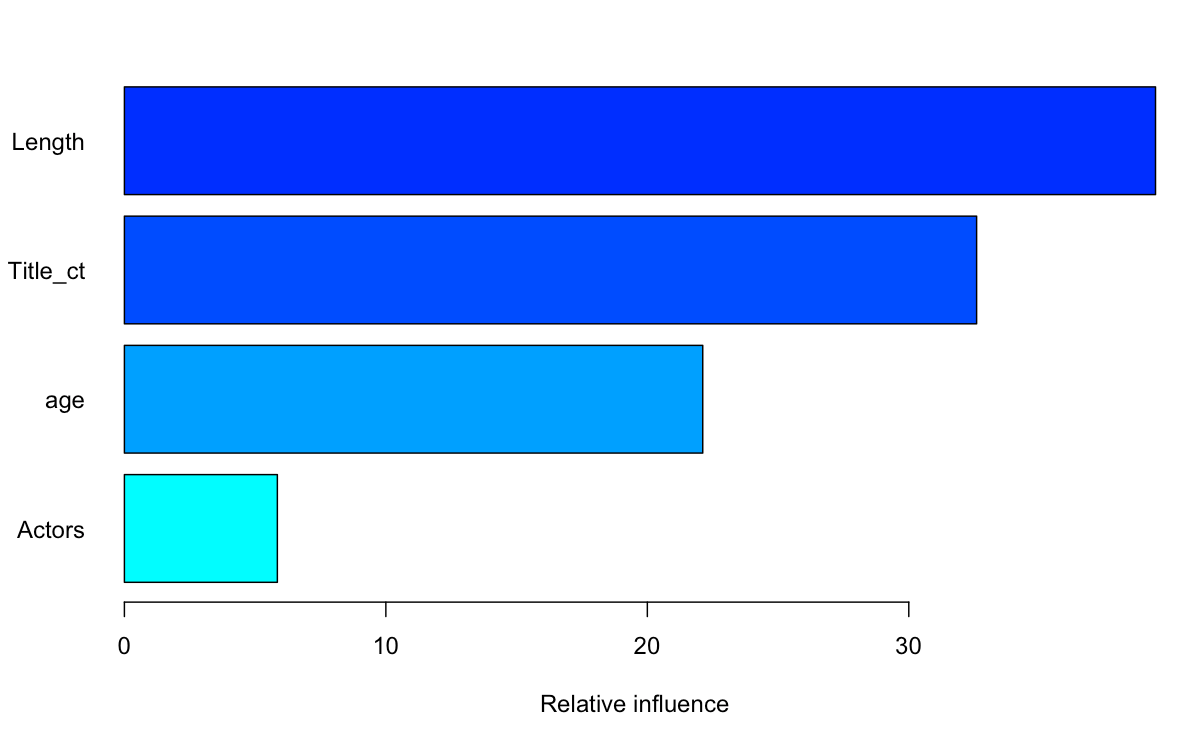
The relative influence (variable importance) plot is generated by taking out the variable of interest and “scramble” all other variables, to measure the change in model deviance in order to gauge the relative influence of that variable. We see the length of the video and number of characters in the video title are the most influential variables.
Partial Dependence Plot (pdp) calculated the relative trend of the prediction when changing the variable of interest, integrating out all other variables. It is somewhat analogous to the added variable plot for regression, except it relaxes linearity assumptions. From these pdp, we see videos with 3-5 min and 16-20 minutes rate higher; we also see people rate videos with shorter titles higher; it’s most interesting to see that viewers prefer either 2 or 4 actors in the same video, while a threesome or orgy (5 or more) are rated lower.
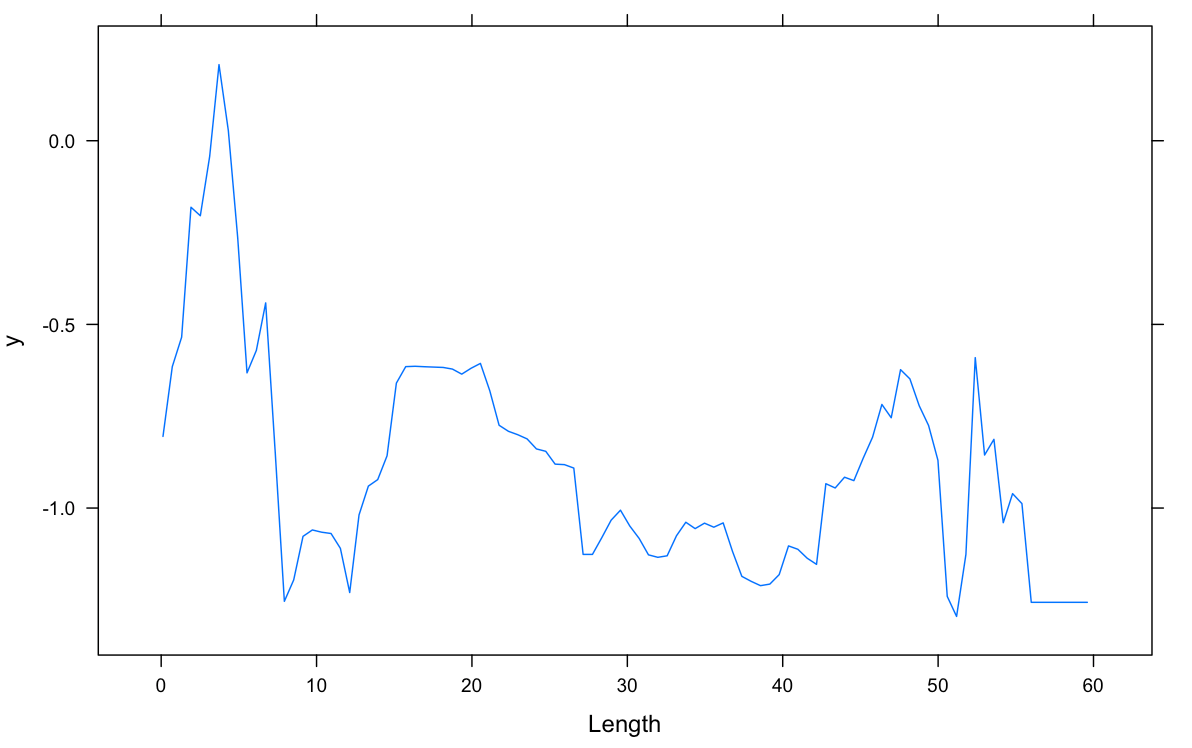 Videos with 3-5 min and 16-20 minutes rate higher
Videos with 3-5 min and 16-20 minutes rate higher
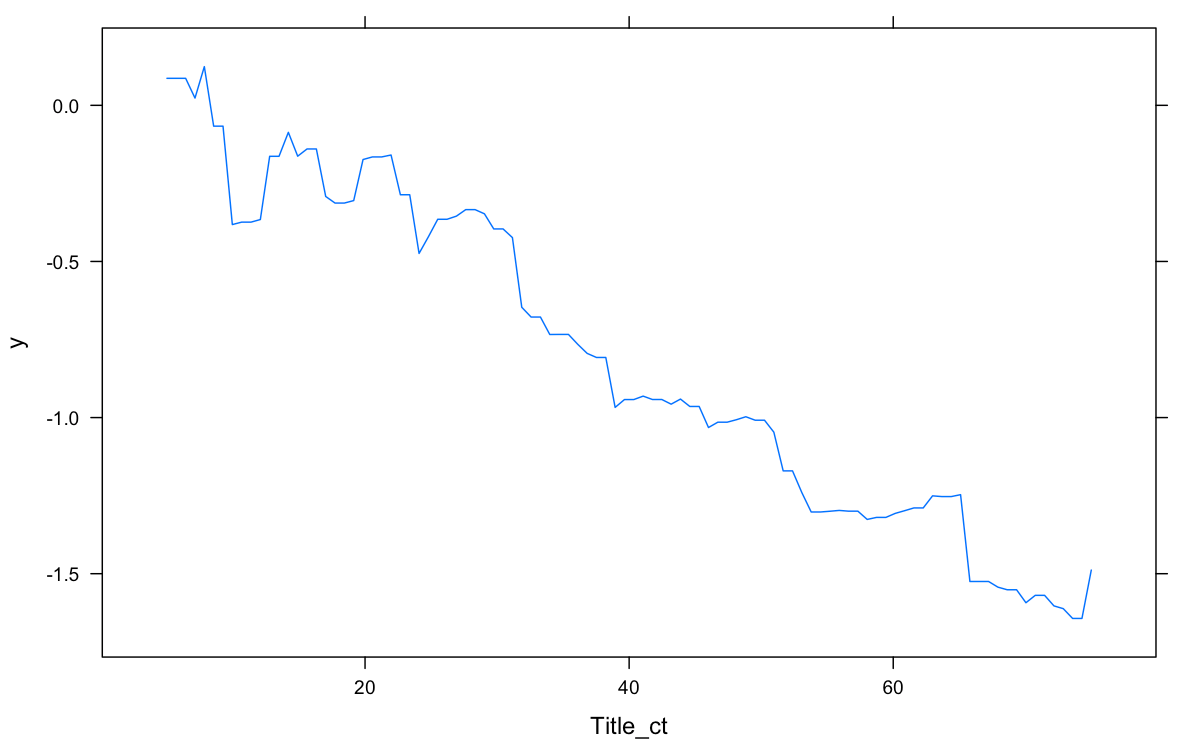 Videos with shorter titles rate higher
Videos with shorter titles rate higher
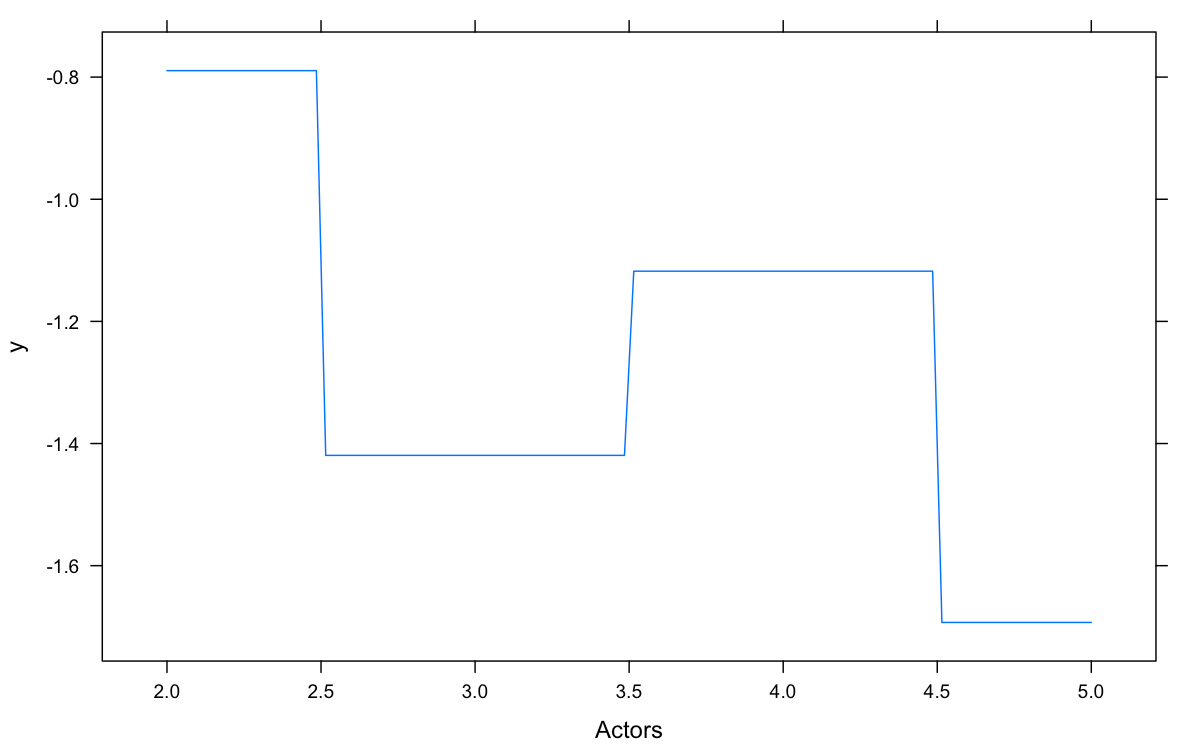 Viewers prefer either 2 or 4 actors in the same video, while a threesome or orgy (5 or more) are rated lower.
Viewers prefer either 2 or 4 actors in the same video, while a threesome or orgy (5 or more) are rated lower.
Model Result Part 2—Porn Star Views:
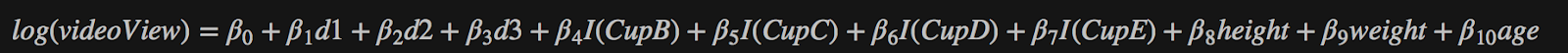 Log-linear regression model, was replaced by GBM while all the predictors remain the same
Log-linear regression model, was replaced by GBM while all the predictors remain the same
I used a GBM model to predict the log(video views) for each star, using their biological variables as predictors. Due to the significant missing data problem with the star’s dimension data, I used multivariate imputation, assuming the data of height and weight could provide information on the dimensions. As a result, I found cup size and age to be the most significant predictors for a star’s video views.
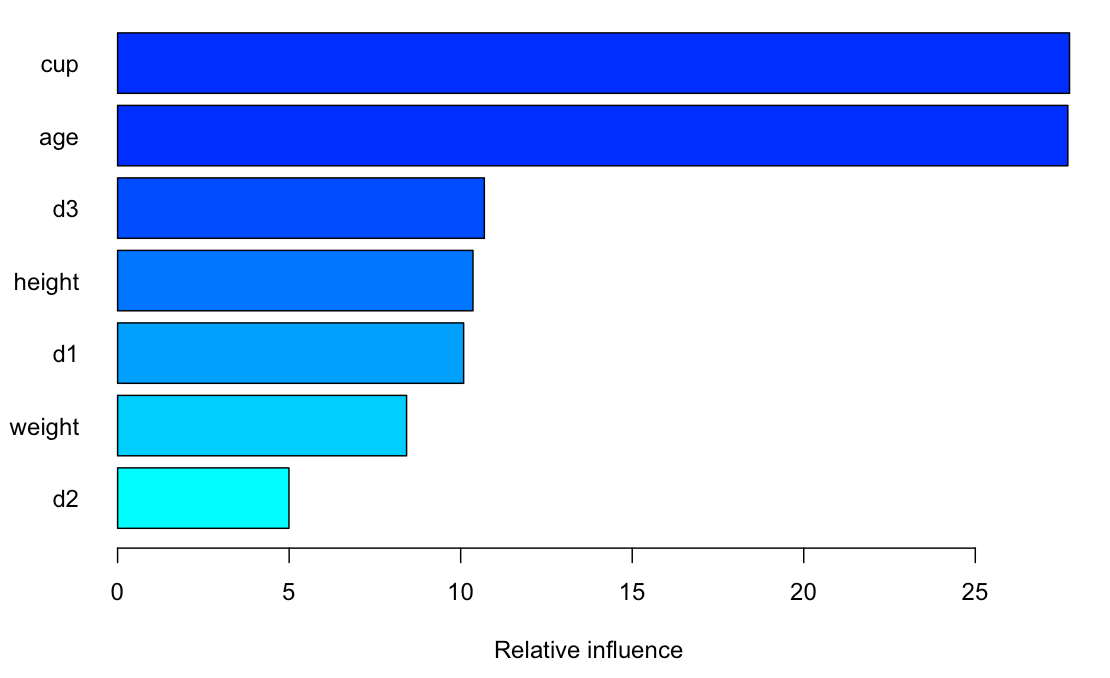 Cup size and age to be the most significant predictors for a star’s video views. D1, D2, and D3 are the 3 dimension metrics.
Cup size and age to be the most significant predictors for a star’s video views. D1, D2, and D3 are the 3 dimension metrics.
As the partial dependence plots indicate, the prime age for a pornstar is around 23. I believe since the biggest porn viewers are teenagers and young adults, they do prefer younger pornstars. A star accumulates popularity and skills after she enters the industry after the legal age of 18, and “ripe” when she is around 23. The age effect from 28 to 45 is nearly flat, signaling that middle age pornstars are in demand by many demographics, from young adult break up to middle-age crisis.
Does size matter? Yes. GBM model found that cup size D, followed by E, are the most coveted boob size for viewers. Unfortunately, stars with cup size A were at a disadvantage. However, this model could be biased significantly since the 73% of the cup size data were imputed.
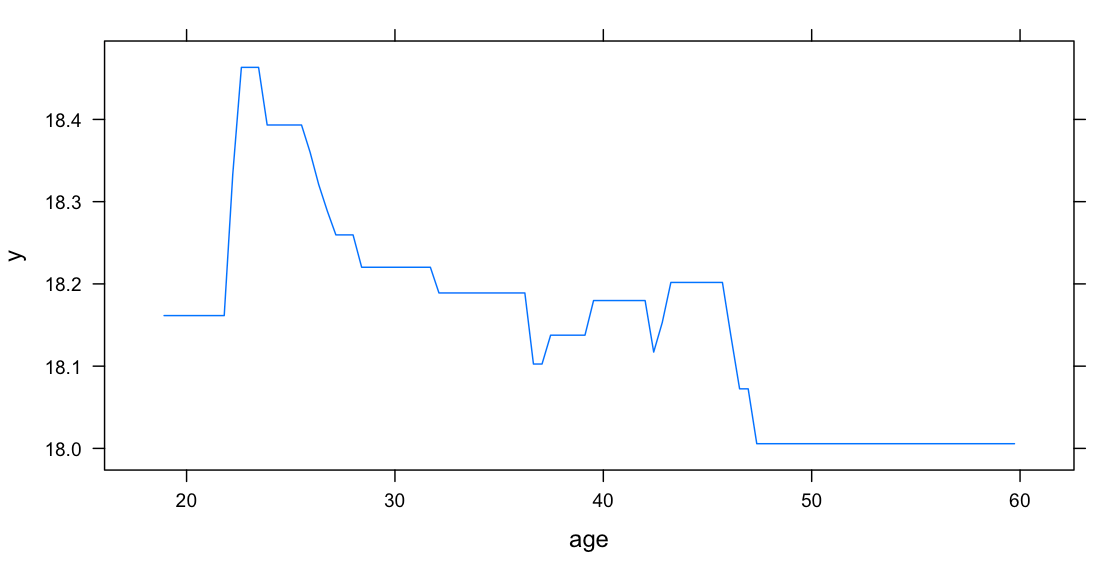 A star accumulates popularity and skills after she enters the industry after the legal age of 18, and “ripe” when she is around 23.
A star accumulates popularity and skills after she enters the industry after the legal age of 18, and “ripe” when she is around 23.
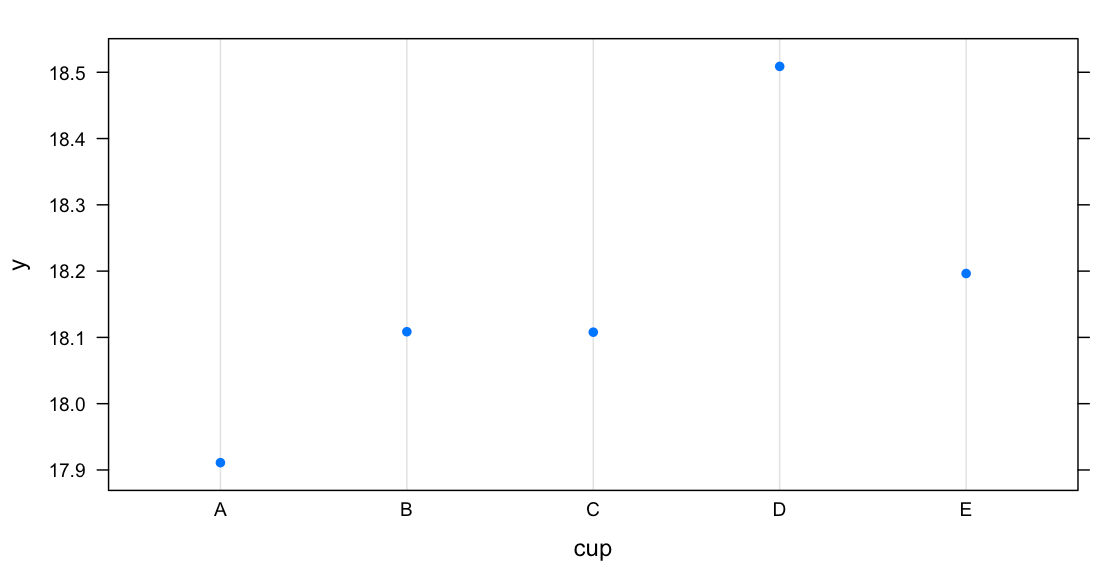 Cup size D, followed by E, are the most coveted boob size for viewers
Cup size D, followed by E, are the most coveted boob size for viewers
Visualization:
In order to visualize the specialty of each pornstar in a scalable way, I constructed a TFIDF word cloud based on texts from each star’s video title. In the bio page, each star has 0-50 videos with title. I tokenized all these titles into a bag of words, with each document denoting each star, and computed TfIdf (term frequency inverse document frequency) for the star vs token matrix. The text corpus underwent many steps of pre-processing, such as removing all the stop-words including pornstars’ names, stemming, and stripping punctuations. In the Shiny App, when we select a pornstar, the code would visualize the star’s top 100 tokens ranked based on their TfIDf score in a word cloud. Playing between having a 1-3 words ngram tokenizer, I found that only 1 word produced the best word cloud, as the bigrams and trigrams are sometimes attaching two unmeaningful words together.
By and large, the wordcloud does a fair representation and differentiation of the pornstar, despite only using up to 50 of the videos listed on her bio-page. For example, the Duke student turned pornstar Belle Knox has a word cloud with most prominent tokens being “Duke ”, “university”, and “tuition” (she started making porn in order to pay the Duke tuition).
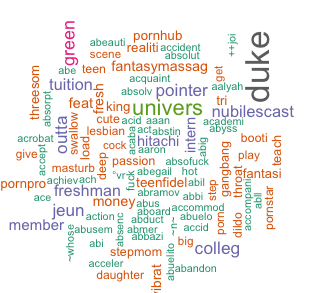 Wordcloud for Belle Knox
Wordcloud for Belle Knox
What do I still need to know?
This project encountered unexpected challenges from html time out, missing data, and model misspecification, and was able to tackle them in a fairly clean way. However, the lack of informative features, absent from the website, such as race and video genre limited the predictive power of the models. The age model also suffers from a small sample size problem (n = 573). I believe had there been more pornstars with detailed bio pages, the model would have been more robust.
The sampling and representation bias is another unsolvable challenge for this project. Because 30% of the pornhub viewers are women (based on 2017 data), it is biased to extrapolate the pornhub viewer behavior to either men and women or just men. The age demographic is also unequally represented. In addition, since most of the pornstars are white women, it is hard to gauge the sexual preferences for the minority demographics.